
¿Por Qué Convertir HL7 v2.x a JSON?
HL7 v2.x fue diseñado en 1987 cuando el texto delimitado por tuberías era la lengua franca de los sistemas sanitarios. Hoy el mundo habla JSON. Las APIs REST, bases de datos NoSQL, índices de Elasticsearch, topics de Kafka y pipelines ETL en la nube esperan JSON de forma nativa. Convertir mensajes HL7 a JSON es el camino más rápido para hacer accesibles décadas de datos clínicos delimitados por tuberías a las herramientas modernas, sin reescribir los motores de interfaz que los generan.
Esta guía cubre los dos formatos de conversión principales (simplificado y estilo HAPI), cómo se manejan las repeticiones de campos y las secuencias de escape, y los patrones de integración prácticos donde el JSON de HL7 es la forma intermedia adecuada.
Anatomía de un Mensaje HL7 v2.x
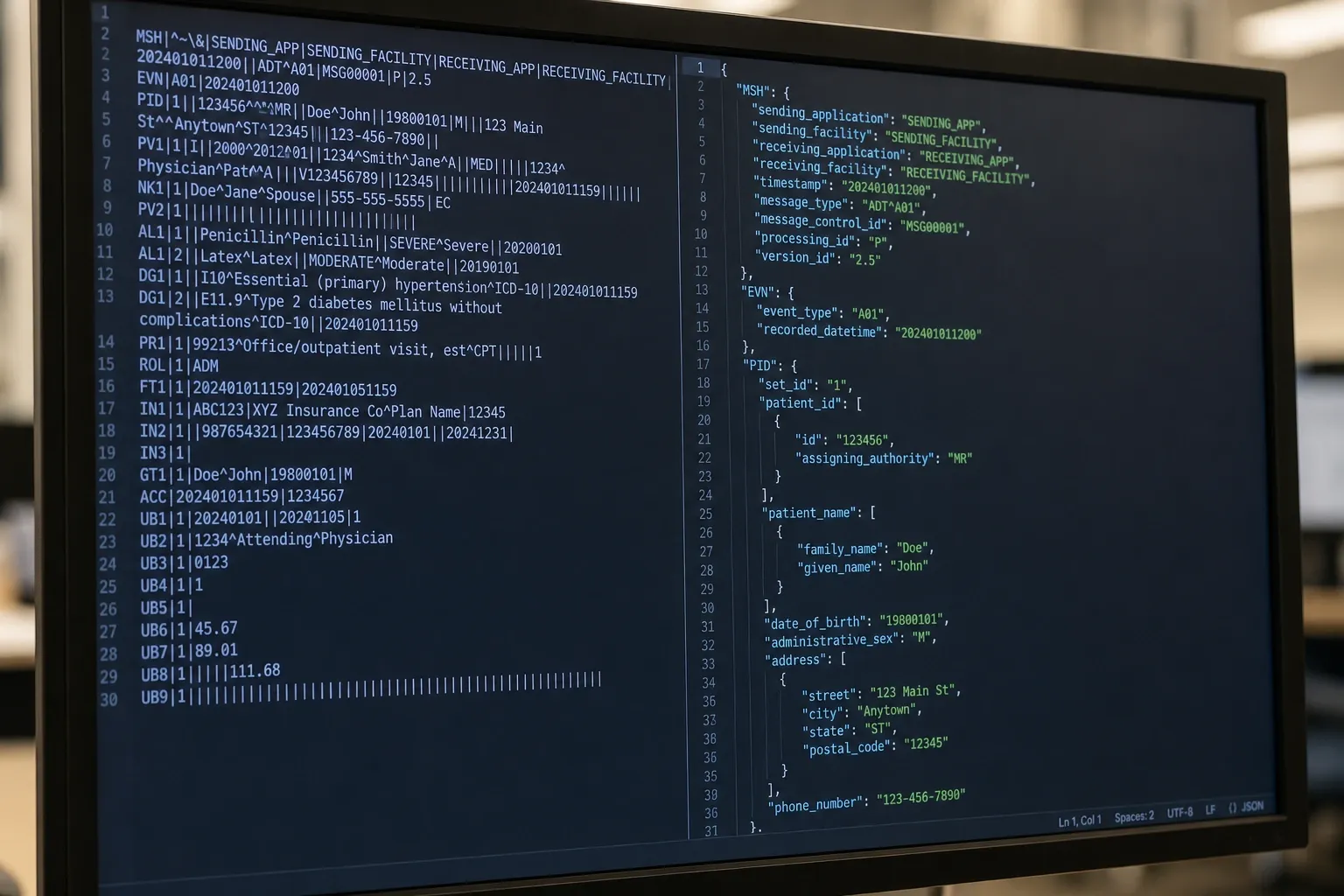
Antes de convertir, comprende qué estás parseando. Un mensaje HL7 v2.x es una secuencia de segmentos separados por retornos de carro (\r). Cada segmento comienza con un identificador de tres caracteres: MSH, PID, OBX, etc. Los campos dentro de un segmento están separados por el carácter separador de campos (| por defecto, definido en MSH-1). Los campos pueden contener:
- Componentes: separados por
^. Ejemplo:Smith^John^A— apellido, nombre, inicial del segundo nombre. - Subcomponentes: separados por
&. Poco frecuentes; usados en tipos de datos complejos como direcciones extendidas. - Repeticiones: separadas por
~. Ejemplo: múltiples identificadores de paciente en PID.3.
Los dos primeros campos del segmento MSH (MSH-1 y MSH-2) definen todos los caracteres separadores y de escape de forma dinámica. Un parser conforme nunca debe codificar de forma rígida |^~\&, sino leerlos del encabezado.
Modo Simplificado: JSON Plano y Rápido
El formato de salida simplificado mapea cada segmento a un objeto JSON con claves de campo de la forma SEG.N, donde N es la posición del campo (basada en 1, según la numeración de campos del estándar HL7). Por ejemplo, el campo del segmento PID en la posición 5 (nombre del paciente) se convierte en clave PID.5.
Una representación JSON simplificada de un segmento PID se parece a esto:
{
"segment": "PID",
"occurrence": 1,
"fields": {
"PID.1": "1",
"PID.3": ["MRN-88412", "", "", "CITY_GENERAL", "MR"],
"PID.5": ["Smith", "Elena", "M"],
"PID.7": "19870623",
"PID.8": "F",
"PID.13": "5559871234"
}
}
Decisiones clave en este formato:
- Campos vacíos →
null. Distingue "no proporcionado" de "clave ausente". - Campos con componentes → arrays. La posición en el array es el índice del componente.
- Campos repetidos → array externo de arrays de componentes internos.
- Campos de un solo valor → cadenas simples para mayor legibilidad.
Este formato es ideal para búsquedas de campos, consultas con jq y reglas ETL ligeras. Es compacto y legible sin requerir conocimiento de tipos de datos HL7 para interpretarlo.
Modo Estilo HAPI: Componentes Nominados para Integración de Sistemas
La librería Java HAPI (HL7 Application Programming Interface) es el parser HL7 v2.x más ampliamente desplegado del mundo. Está integrada en el motor Bridges de Epic, Rhapsody, Ensemble e innumerables servidores de integración personalizados. Cuando HAPI serializa un mensaje a JSON, nombra cada componente usando el descriptor del tipo de dato HL7 en lugar de un índice numérico.
Para el mismo campo PID.5 de nombre del paciente (tipo de dato XPN — Nombre Extendido de Persona), el JSON estilo HAPI se parece a:
{
"PID.5": {
"FN": { "surname": "Smith" },
"given": "Elena",
"middleInitialOrName": "M"
}
}
Esta verbosidad vale la pena cuando construyes un sistema que debe interoperar con componentes basados en HAPI. Si tu servidor de integración emite JSON HAPI y tu consumidor downstream lo espera, debes coincidir con la estructura exacta de claves o escribir un adaptador. Usar el modo estilo HAPI desde tu convertidor evita esa capa de adaptador por completo.
Manejo de Repeticiones de Campos
Las repeticiones son uno de los aspectos del HL7-a-JSON más comúnmente mal manejados. Un campo puede repetirse — por ejemplo, PID.3 (lista de identificadores del paciente) a menudo tiene múltiples repeticiones: una para el MRN, otra para el identificador nacional del paciente, otra para el ID del seguro. El carácter ~ separa las repeticiones.
En modo simplificado, un campo repetido se convierte en un array externo de valores de componentes internos. Los convertidores que no manejan las repeticiones colapsan todos los valores en la primera repetición, descartando silenciosamente los identificadores. Al procesar PID.3 para la concordancia de pacientes, esto puede producir decisiones de fusión incorrectas.
Secuencias de Escape HL7
HL7 usa un mecanismo de escape con barra invertida para incrustar los cinco caracteres separadores reservados dentro de los valores de campo. Los escapes estándar son:
\F\→ separador de campo (|)\S\→ separador de componente (^)\R\→ separador de repetición (~)\T\→ separador de subcomponente (&)\E\→ carácter de escape (\)
Los convertidores deben decidir si resolver estos a sus caracteres literales en la salida JSON o mantenerlos codificados.
Mantener codificado (descifrado desactivado) cuando necesitas fidelidad de ida y vuelta — el JSON podría después re-serializarse de vuelta a HL7 y las secuencias de escape originales deben preservarse.
Resolver a literales (descifrado activado) cuando el JSON es una forma terminal — se almacenará, indexará o mostrará como texto y las secuencias de barra invertida confundirían a los consumidores downstream.
Campos Nulos y Actualizaciones de Base de Datos
En HL7 v2.x, hay una distinción semántica entre un campo ausente y un campo explícitamente nulo. Un campo vacío (||) significa "no proporcionado — dejar el valor existente sin cambios en el sistema downstream". Un campo que contiene solo comillas dobles (|""|) significa "eliminar/limpiar explícitamente el valor existente".
Esta distinción es crítica en los mensajes ADT^A08 (actualización del paciente), donde solo se envían los campos modificados. Si tu convertidor JSON colapsa los campos vacíos a claves JSON ausentes, un procesador de actualizaciones no puede distinguir "sin cambio" de "limpiar este campo". El convertidor mapea campos vacíos a JSON null (clave presente, valor nulo) para preservar esta distinción.
Seguimiento de Ocurrencias de Segmentos
Muchos mensajes HL7 contienen segmentos repetidos. Un mensaje de resultado ORU^R01 puede tener 20 segmentos OBX, uno por medición de laboratorio. El convertidor asigna un índice de ocurrencia comenzando en 1 a cada tipo de segmento, por lo que el 3er OBX se emite como {"segment":"OBX","occurrence":3,...}. Esto hace que la lógica dependiente del orden sea segura.
Patrones de Integración Comunes
Patrón 1: Feeds HL7 a Elasticsearch
Los motores de integración hospitalaria procesan miles de mensajes HL7 por hora. Almacenarlos como texto delimitado por tuberías los hace no buscables. Convertir cada mensaje a JSON antes de indexarlo en Elasticsearch permite consultas como "todos los eventos ADT^A01 para la instalación X entre las fechas Y y Z" o "todos los resultados ORU donde OBX.5 contiene 'crítico'". El formato de salida simplificado funciona bien aquí.
Patrón 2: Preparación para Conversión FHIR
La conversión de HL7 v2.x a FHIR R4 es el proyecto de modernización de integración dominante en sanidad hoy. La lógica de conversión lee campos fuente (PID.5 → Patient.name, PID.7 → Patient.birthDate) y construye recursos FHIR. Usar HL7 a JSON como paso intermedio desacopla la lógica de parseo de la lógica de transformación. Parsea una vez a JSON, transforma JSON a FHIR — ahora tu código de mapeo FHIR trabaja con herramientas JSON estándar.
Patrón 3: Demografía ADT a MDM
Los sistemas de Gestión de Datos Maestros (MDM) mantienen registros de pacientes de empresa. Consumen feeds ADT para mantener actualizados los datos demográficos. Convertir mensajes ADT^A08 a JSON, luego aplicar operaciones JSON Patch al registro MDM, produce un rastro de auditoría limpio: cada operación de parche corresponde a un campo HL7 modificado, y el JSON original preserva la distinción nulo-vs-ausente.
Patrón 4: Resultados de Laboratorio a Dashboards de Análisis
Los mensajes ORU^R01 llevan los segmentos de observación OBX que alimentan los dashboards de laboratorio. Convertir segmentos OBX a JSON permite la inserción directa en bases de datos de series de tiempo (InfluxDB, TimescaleDB) o almacenes analíticos (BigQuery, Redshift) donde el valor, unidades, rango de referencia e indicador de anormalidad se convierten en columnas consultables.
Lista de Verificación para Seguridad de Ida y Vuelta
Si tu caso de uso requiere convertir HL7 a JSON y de vuelta a HL7, verifica estos puntos:
- Opción de descifrado desactivada — las secuencias de escape deben permanecer codificadas para la re-serialización
- Campos nulos preservados — los campos ausentes no deben omitirse silenciosamente
- Orden de repetición mantenido — el orden del array en el JSON debe coincidir con el orden de repetición original
- Orden de ocurrencia mantenido — los segmentos repetidos deben serializarse a HL7 en el orden de ocurrencia original
El modo estilo HAPI maneja todos los anteriores. El modo simplificado no está diseñado para viajes de ida y vuelta porque pierde la semántica de nombres de componentes.
Consideraciones de Seguridad y Privacidad
Los mensajes HL7 v2.x frecuentemente contienen Información de Salud Protegida (PHI en inglés): nombres de pacientes, números de historia clínica, fechas de nacimiento, diagnósticos, valores de laboratorio. Al construir un pipeline que convierte HL7 a JSON, aplica los mismos controles de acceso y requisitos de cifrado a la salida JSON que a los mensajes HL7 originales. El JSON no es inherentemente más o menos sensible que el HL7 — ambos formatos contienen el mismo PHI.
La conversión basada en navegador (como se implementa en esta herramienta) es segura para el PHI porque no se transmiten datos. Para pipelines del lado del servidor, asegúrate de que el JSON HL7 se transmite sobre TLS, se almacena en reposo con el cifrado apropiado y está sujeto al mismo registro de auditoría que los mensajes HL7 sin procesar en tu entorno cubierto por HIPAA.
Conclusión
Convertir HL7 v2.x a JSON es uno de los pasos más prácticos en la modernización de la integración sanitaria. El modo simplificado te da una representación rápida y consultable para la mayoría de los casos de uso. El modo estilo HAPI te da fidelidad estructural para la interoperabilidad con HAPI de Java y los escenarios de ida y vuelta. Comprender las repeticiones, la semántica nula y el manejo de escapes asegura que tus conversiones sean completas y correctas, no solo sintácticamente válidas. Usa el Convertidor HL7 a JSON basado en navegador para probar mensajes de forma interactiva antes de incrustar la lógica de conversión en tu pipeline.