
Why Convert HL7 v2.x to JSON?
HL7 v2.x was designed in 1987 when pipe-delimited text was the lingua franca of healthcare systems. Today, the world speaks JSON. REST APIs, NoSQL databases, Elasticsearch indexes, Kafka topics, and cloud ETL pipelines all expect JSON natively. Converting HL7 messages to JSON is the fastest path to making decades of pipe-delimited clinical data accessible to modern tooling — without rewriting the interface engines that generate it.
This guide covers the two major conversion formats (simplified and HAPI-style), how field repetitions and escape sequences are handled, and practical integration patterns where HL7 JSON is the right intermediate form.
Anatomy of an HL7 v2.x Message
Before converting, understand what you are parsing. An HL7 v2.x message is a sequence of segments separated by carriage returns (\r). Each segment starts with a three-character identifier: MSH, PID, OBX, etc. Fields within a segment are separated by the field separator character (| by default, defined in MSH-1). Fields can contain:
- Components: separated by
^. Example:Smith^John^A— family name, given name, middle initial. - Subcomponents: separated by
&. Rare; used in complex data types like extended addresses. - Repetitions: separated by
~. Example:MRN-001~~~HOSP^MR~SSN-REDACTED— two patient identifier repetitions.
The MSH segment's first two fields (MSH-1 and MSH-2) define all separator and escape characters dynamically. A compliant parser must never hard-code |^~\& — it must read them from the header. This matters when converting: if your parser hard-codes the separators, it will break on the rare but valid message that customizes them.
Simplified Mode: Fast Flat JSON
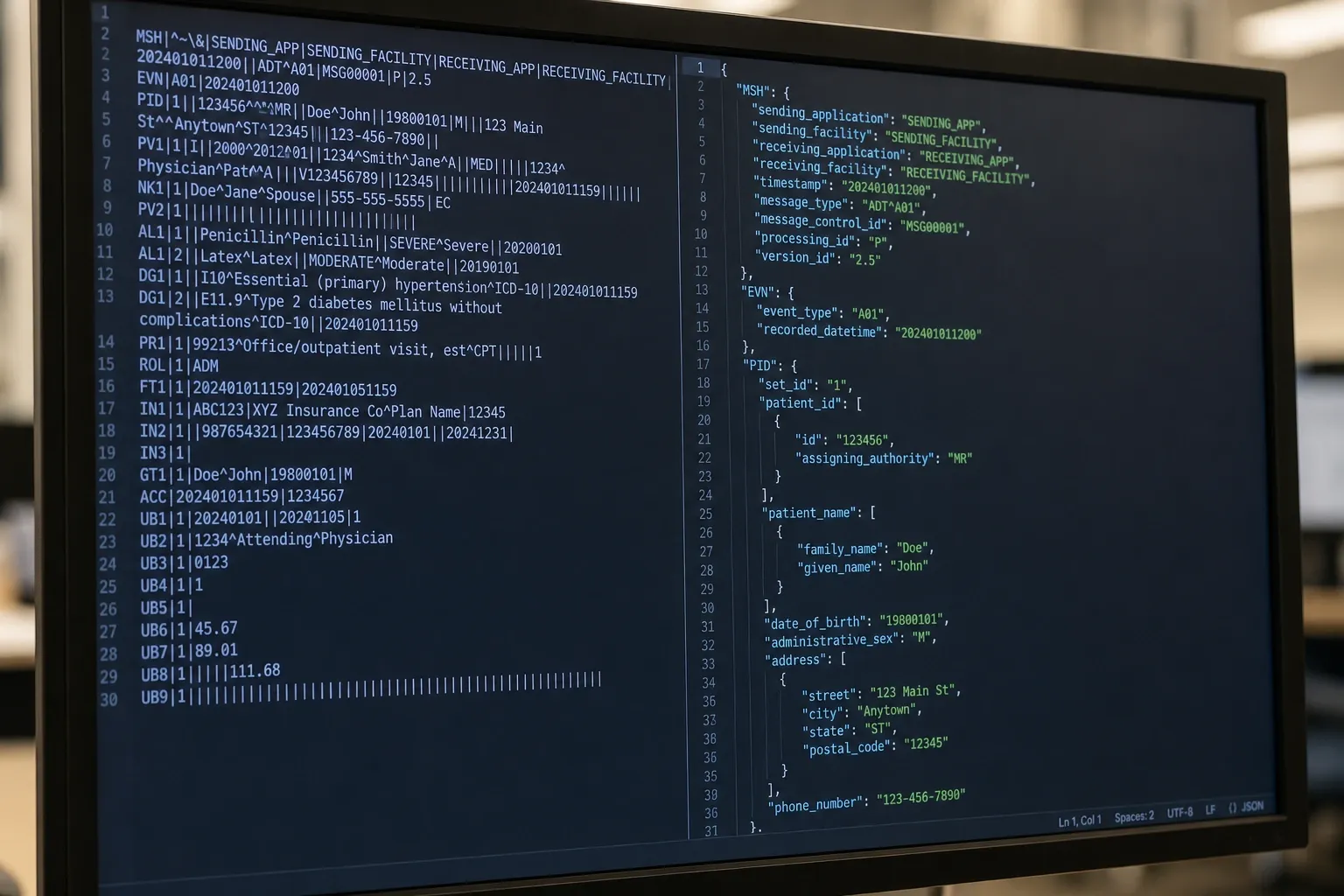
The simplified output format maps each segment to a JSON object with field keys of the form SEG.N, where N is the field position (1-based, per the HL7 standard's own field numbering). For example, the PID segment field at position 5 (patient name) becomes key PID.5.
A simplified JSON representation of a PID segment looks like this:
{
"segment": "PID",
"occurrence": 1,
"fields": {
"PID.1": "1",
"PID.3": ["MRN-88412", "", "", "CITY_GENERAL", "MR"],
"PID.5": ["Smith", "Elena", "M"],
"PID.7": "19870623",
"PID.8": "F",
"PID.11": ["742 Evergreen Terrace", "", "Springfield", "IL", "62704", "USA"],
"PID.13": "5559871234"
}
}
Key decisions in this format:
- Empty fields →
null. Distinguishes "not provided" from "absent key". - Fields with components → arrays. Position in the array is the component index.
- Repeated fields → outer array of inner component arrays.
- Single-value fields → plain strings for readability.
This format is ideal for field lookups, jq queries, and lightweight ETL rules. It is compact and readable without requiring HL7 data-type knowledge to interpret.
HAPI-Style Mode: Named Components for System Integration
The HAPI (HL7 Application Programming Interface) Java library is the most widely deployed HL7 v2.x parser in the world. It is embedded in Epic's Bridges engine, Rhapsody, Ensemble, and countless custom integration servers. When HAPI serializes a message to JSON, it names each component using the HL7 data-type descriptor rather than a numeric index.
For the same PID.5 patient name field (data type XPN — Extended Person Name), HAPI-style JSON looks like:
{
"PID.5": {
"FN": { "surname": "Smith" },
"given": "Elena",
"middleInitialOrName": "M"
}
}
This verbosity pays off when you are building a system that must interoperate with HAPI-based components. If your integration server emits HAPI JSON and your downstream consumer expects it, you must match the exact key structure or write an adapter. Using HAPI-style mode from your converter avoids that adapter layer entirely.
When to choose HAPI-style over simplified:
- Your downstream system is a Java application using the HAPI library
- You need to serialize back to HL7 from the JSON (HAPI-style preserves enough structure)
- You are building a schema-validated JSON store where component semantics must be explicit
Handling Field Repetitions
Repetitions are one of the most commonly mishandled aspects of HL7-to-JSON conversion. A field can repeat — for example, PID.3 (patient identifier list) often has multiple repetitions: one for the MRN, one for the national patient identifier, one for the insurance ID. The ~ character separates repetitions.
In simplified mode, a repeated field becomes an outer array of inner component values:
"PID.3": [ ["MRN-88412", "", "", "CITY_GENERAL", "MR"], ["SSN-REDACTED", "", "", "US-SSN", "SS"] ]
Converters that fail to handle repetitions collapse all values into the first repetition, silently dropping identifiers. When processing PID.3 for patient matching, this can produce incorrect merge decisions — a patient with an MRN and a payer ID looks like they have only an MRN. Always verify that your converter distinguishes repetition separators from component separators.
HL7 Escape Sequences
HL7 uses a backslash escape mechanism to embed the five reserved separator characters within field values. The standard escapes are:
\F\→ field separator (|)\S\→ component separator (^)\R\→ repetition separator (~)\T\→ subcomponent separator (&)\E\→ escape character (\)
Converters must decide whether to resolve these to their literal characters in the JSON output or keep them encoded.
Keep encoded (unescape off) when you need round-trip fidelity — the JSON may later be re-serialized back to HL7 and the original escape sequences must be preserved. For example, a patient note field containing a pipe character must keep \F\ in the JSON so the HL7 generator can encode it correctly on the way back.
Resolve to literals (unescape on) when the JSON is a terminal form — it will be stored, indexed, or displayed as text and the backslash sequences would confuse downstream consumers.
Null Fields and Database Updates
In HL7 v2.x, there is a semantic distinction between an absent field and an explicitly null field. An empty field (||) means "not provided — leave the existing value unchanged in the downstream system". A field containing only double quotes (|""|) means "explicitly delete/clear the existing value".
This distinction is critical in ADT^A08 (patient update) messages, where only changed fields are sent. If your JSON converter collapses empty fields to absent JSON keys, an update processor cannot distinguish "no change" from "clear this field" — and will incorrectly preserve data that should have been deleted.
The converter maps empty fields to JSON null (key present, value null) to preserve this distinction. If you are using the JSON to drive a database update, treat null as "overwrite with null" and absent key as "do not touch".
Segment Occurrence Tracking
Many HL7 messages contain repeated segments. An ORU^R01 result message might have 20 OBX segments — one per lab measurement. An ADT^A01 admission message might have 5 DG1 diagnosis segments. The converter assigns an occurrence index starting at 1 to each segment type, so the 3rd OBX is emitted as {"segment":"OBX","occurrence":3,...}.
This makes order-dependent logic safe: you can sort the output array by occurrence and know you are processing segments in the same order they appeared in the original message. Relational databases can use the occurrence index as a sort key when storing multiple OBX rows for the same message.
Common Integration Patterns
Pattern 1: HL7 Feeds to Elasticsearch
Hospital integration engines process thousands of HL7 messages per hour. Storing them as raw pipe-delimited text makes them unsearchable. Converting each message to JSON before indexing in Elasticsearch enables queries like "all ADT^A01 events for facility X between dates Y and Z" or "all ORU results where OBX.5 contains 'critical'". The simplified output format works well here because Elasticsearch's dynamic mapping handles flat key-value structures efficiently.
Pattern 2: FHIR Conversion Staging
HL7 v2.x to FHIR R4 conversion is the dominant integration modernization project in healthcare today. The conversion logic reads source fields (PID.5 → Patient.name, PID.7 → Patient.birthDate) and constructs FHIR resources. Using HL7-to-JSON as an intermediate step decouples the parsing logic from the transformation logic. Parse once to JSON, transform JSON to FHIR — now your FHIR mapping code works with standard JSON tools rather than requiring an HL7-specific parser at every step.
Pattern 3: ADT Demographics to MDM
Master Data Management (MDM) systems maintain enterprise patient registries. They consume ADT feeds to keep demographic data current. Converting ADT^A08 (patient update) messages to JSON, then applying JSON Patch operations to the MDM record, produces a clean audit trail: each patch operation corresponds to a changed HL7 field, and the original JSON preserves the null-vs-absent distinction needed to handle explicit clears.
Pattern 4: Lab Results to Analytics Dashboards
ORU^R01 messages carry the OBX observation segments that feed lab dashboards and clinical decision support. Converting OBX segments to JSON enables direct insertion into time-series databases (InfluxDB, TimescaleDB) or analytical stores (BigQuery, Redshift) where the value, units, reference range, and abnormal flag become queryable columns. Use the occurrence index as the row ordering key to preserve the panel order.
Round-Trip Safety Checklist
If your use case requires converting HL7 to JSON and back to HL7, check these points before relying on the output:
- Unescape option off — escape sequences must remain encoded for re-serialization
- Null fields preserved — absent fields must not be silently omitted
- Repetition order maintained — array order in the JSON must match the original repetition order
- Occurrence order maintained — repeated segments must serialize to HL7 in the original occurrence order
- MSH metadata preserved — encoding characters, sending/receiving application and facility, message control ID
HAPI-style mode handles all of the above. Simplified mode is not designed for round-trips because it loses component name semantics. A round-trip from simplified JSON to HL7 requires an additional component-order assumption that the simplified format does not encode.
Security and Privacy Considerations
HL7 v2.x messages frequently contain Protected Health Information (PHI): patient names, medical record numbers, birthdates, diagnoses, lab values. When building a pipeline that converts HL7 to JSON, apply the same access controls and encryption requirements to the JSON output as to the original HL7 messages. JSON is not inherently more or less sensitive than HL7 — both formats contain the same PHI.
Browser-based conversion (as implemented in this tool) is PHI-safe because no data is transmitted. For server-side pipelines, ensure that HL7 JSON is transmitted over TLS, stored at rest with appropriate encryption, and subject to the same audit logging as raw HL7 messages in your HIPAA-covered environment.
Conclusion
Converting HL7 v2.x to JSON is one of the most practical steps in healthcare integration modernization. Simplified mode gives you a fast, queryable representation for most use cases. HAPI-style mode gives you structural fidelity for Java HAPI interoperability and round-trip scenarios. Understanding repetitions, null semantics, and escape handling ensures your conversions are complete and correct — not just syntactically valid. Use the browser-based HL7 to JSON Converter to test messages interactively before embedding conversion logic in your pipeline.