Por Que PID y PV1 Importan Tanto al Mapear ADT a JSON
Cuando un equipo dice que esta convirtiendo mensajes ADT a JSON, casi siempre esta intentando preservar dos verdades al mismo tiempo: quien es el paciente y en que contexto asistencial se encuentra ese paciente ahora mismo. En la mayoria de los flujos HL7 v2.x de admision, alta y traslado, esas dos verdades viven sobre todo en los segmentos PID y PV1. PID contiene identidad y demografia. PV1 contiene el contexto de visita y encounter. Si cualquiera de los dos se aplana demasiado pronto, el JSON resultante puede seguir pareciendo correcto mientras pierde significado que despues necesitan un EMPI, una capa analitica, un bus de eventos o un mapeador FHIR.
Este articulo explica como mapear PID y PV1 a JSON sin perder esa semantica operativa. Complementa nuestras guias sobre conversion de HL7 v2 a JSON, referencia de campos de segmentos HL7 y uso de JSON HL7 en pipelines de ingesta FHIR. Para validar mensajes reales, puedes inspeccionarlos con el Visor HL7 y probar el comportamiento del mapeo con el Convertidor HL7 a JSON.
Que Representa PID en un Entorno Real
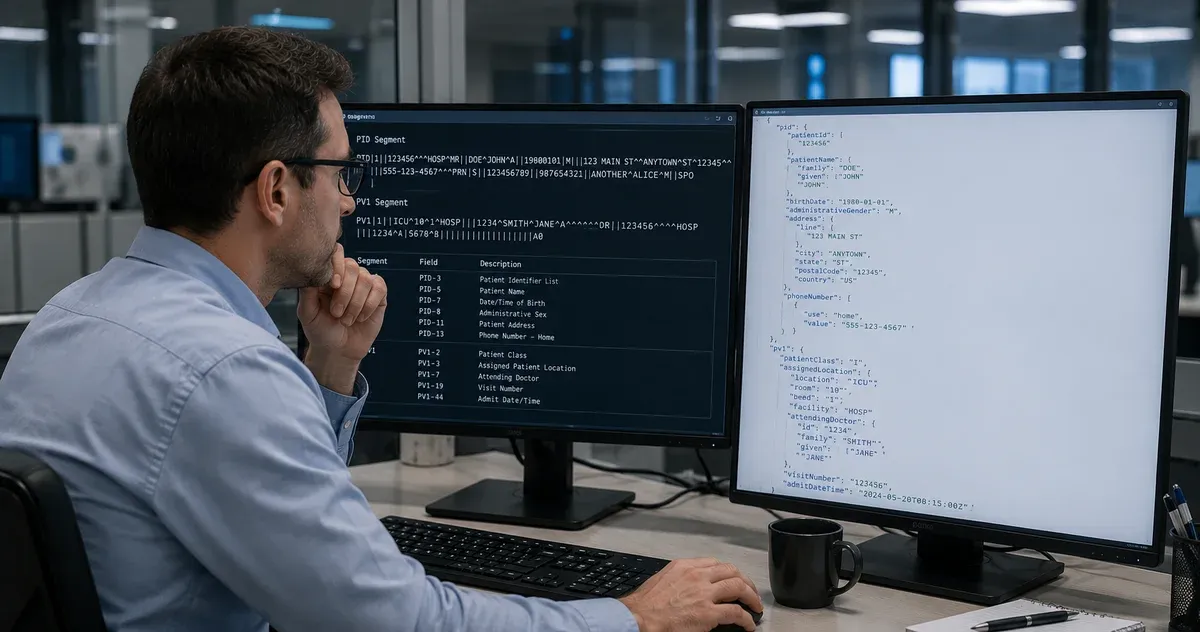
El segmento PID es la columna demografica de un mensaje ADT. Alli suelen vivir los identificadores de paciente que alimentan la conciliacion, el nombre tal como lo introdujo admision, la fecha de nacimiento, el sexo administrativo, la direccion, los telefonos y a veces detalles como indicadores de fallecimiento o codigos de grupo etnico. En produccion, PID rara vez es un objeto simple de una sola fila. Hay campos repetidos, componentes estructurados y mucha variacion segun el centro emisor. Un modelo JSON que asuma un solo identificador, un solo nombre y un solo telefono se rompe en cuanto se encuentra con trafico real.
Por eso conviene preservar primero la estructura HL7 y derivar despues propiedades amigables. PID-3, PID-5, PID-11 y PID-13 son los ejemplos mas claros. PID-3 es repetible y puede traer a la vez el MRN, un identificador enterprise y un identificador externo. PID-5 puede repetirse si se transmite nombre legal y alias. PID-11 puede tener mas de una direccion y PID-13 puede contener varios valores de telecomunicacion. Si tu JSON reduce todo eso a un unico string, obligas a cada consumidor downstream a adivinar que repeticion sobrevivio y cual se perdio.
Que Representa PV1 en un Entorno Real
Si PID responde a la pregunta de quien es el paciente, PV1 responde a la pregunta de que episodio asistencial describe el mensaje. Clase del paciente, ubicacion asignada, tipo de admision, medico responsable, servicio hospitalario, numero de visita, fecha de ingreso y fecha de alta se concentran aqui. En flujos centrados en encounter, PV1 es el segmento que determina si el sistema receptor interpreta el mensaje como un ingreso, una visita ambulatoria, una estancia en urgencias o un traslado interno.
Eso convierte a PV1 en un segmento critico para analitica, bed management y transformacion a FHIR. Un registro de paciente sin PV1 todavia puede servir para conciliacion demografica. Un encounter sin un PV1 fiable es mucho menos util. Las capas downstream suelen depender de campos como PV1-2, PV1-3, PV1-7, PV1-19, PV1-44 y PV1-45 para crear estados de visita coherentes y reglas operativas reproducibles.
Empieza con un JSON Canonico y sin Perdida
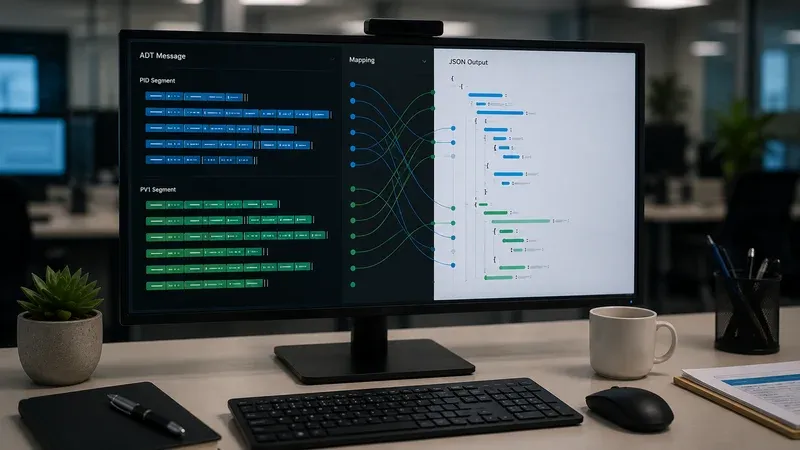
La estrategia mas segura consiste en construir primero un JSON canonico cercano a la semantica HL7 y despues derivar de ahi objetos mas comodos para aplicaciones. En la capa canonica, cada segmento mantiene su ocurrencia y cada campo mantiene su posicion HL7. Eso significa que el JSON puede incluir claves como PID.3, PID.5, PV1.3 o PV1.44 antes de renombrarlas a etiquetas de negocio. No es porque los numeros sean mas bonitos. Es porque son estables, trazables y faciles de comparar con el mensaje original durante el soporte.
Un ejemplo sencillo podria verse asi:
{
"PID": {
"PID.3": [
["884422", "", "", ["CITY_GENERAL"], "MR"],
["99887766", "", "", ["STATE_MPI"], "PI"]
],
"PID.5": [["Lopez", "Ana", "Maria"]],
"PID.7": "19841012",
"PID.11": [["12 Harbor Ave", "", "Boston", "MA", "02110", "USA"]]
},
"PV1": {
"PV1.2": "I",
"PV1.3": ["ICU", "12", "B", "MAIN"],
"PV1.7": [["12345", "Nguyen", "Linh"]],
"PV1.19": ["VIS-20260428-17"],
"PV1.44": "20260428103000"
}
}
Una vez que existe esa capa, ya puedes derivar propiedades como patient.primaryMrn, patient.legalName, encounter.class o encounter.location.room. La regla clave es que esos campos de conveniencia nunca sean la unica copia de la informacion.
Como Mapear PID-3 sin Perder Identificadores
PID-3 es el campo que deja en evidencia los modelos JSON debiles. En muchos hospitales contiene varias identidades para el mismo paciente, con distintas authorities y distintos tipos. La representacion correcta en JSON es por tanto un array de repeticiones, no un unico valor escalar. Cada repeticion debe mantener sus componentes para que la logica posterior pueda decidir cual es el MRN, cual es el identificador enterprise y cual pertenece a un tercero externo.
Desde esa capa canonica puedes derivar una lista normalizada de identificadores como esta:
"patientIdentifiers": [
{
"id": "884422",
"assigningAuthority": "CITY_GENERAL",
"type": "MR",
"isPrimary": true
},
{
"id": "99887766",
"assigningAuthority": "STATE_MPI",
"type": "PI",
"isPrimary": false
}
]
Esta forma derivada es mas facil de consumir desde codigo, pero solo funciona si primero preservaste la estructura de repeticiones original. Los equipos que reducen PID-3 al primer valor suelen descubrir el error despues, cuando aparecen duplicados de paciente, fallos de matching o inconsistencias de seguros.
Como Mapear PID-5, PID-11 y PID-13
Los nombres, direcciones y telefonos del paciente son tipos compuestos con mucha mas informacion de la que parece. PID-5 deberia preservarse como una o varias repeticiones XPN, aunque luego publiques un nombre completo para uso visual. PID-11 deberia mantener por separado calle, ciudad, estado, codigo postal, pais y tipo de direccion. PID-13 deberia conservar la estructura del telecom en lugar de quedarse solo con los digitos, porque los codigos de uso y de equipo a veces importan en flujos posteriores.
Una buena representacion derivada separa las necesidades de interfaz de la verdad canonica. Puedes exponer patient.displayName para una UI y patient.addresses para acceso normalizado, pero seguir conservando los arrays fuente por posicion HL7. Ese enfoque tambien hace que la comparacion con el Visor HL7 sea mucho mas directa cuando hay que explicar por que un dato se mapeo de una forma concreta.
Como Llevar PV1-2 y PV1-3 al Contexto de Encounter
PV1-2 y PV1-3 son el nucleo del contexto de visita. PV1-2 define la clase del paciente. PV1-3 define la ubicacion asignada. Juntos responden a la pregunta operacional mas frecuente en capas downstream: donde esta el paciente y en que tipo de visita se encuentra. La tentacion habitual es condensar PV1-3 en un string como ICU-12-B. Eso puede valer para mostrarlo en pantalla, pero no para logica de negocio. El point of care, la habitacion, la cama y la instalacion deben seguir siendo accesibles por separado.
Un objeto derivado robusto podria verse asi:
"encounter": {
"class": "I",
"location": {
"pointOfCare": "ICU",
"room": "12",
"bed": "B",
"facility": "MAIN"
}
}
Esta es la forma que muchas aplicaciones quieren consumir, pero debe seguir siendo trazable a PV1.2 y PV1.3. Cuando aparece un problema de routing o de censo, la diferencia entre un mapeo transparente y uno opaco se convierte en muchas horas de soporte.
Los Proveedores y el Numero de Visita Tambien Necesitan Estructura
PV1-7, PV1-8, PV1-9 y PV1-17 suelen contener identidades de profesionales que luego se vinculan a directorios clinicos o referencias FHIR. No son simplemente nombres. Son campos compuestos y a menudo repetibles. Conviene preservar por separado el identificador y la parte legible. La misma cautela aplica a PV1-19, el numero de visita. No debe confundirse con el numero de cuenta ni con el identificador del paciente. En muchos entornos ADT es la mejor clave para relacionar varios mensajes de movimiento con un mismo ciclo de encounter.
Los tiempos tambien importan. PV1-44 y PV1-45 deberian conservar la forma HL7 original o su equivalente ISO ya parseado, y preferiblemente ambas. Los equipos de analitica suelen preferir timestamps normalizados. Los analistas de interfaces a menudo quieren el literal HL7 para comparar auditorias. Mantener los dos evita discusiones innecesarias sobre que capa debe parsear la fecha.
Semantica de Nulos, Actualizaciones Parciales y Mensajes A08
Las actualizaciones ADT son el punto donde un mapeo con perdida se vuelve peligroso. En un A08, algunos campos no aparecen porque nada ha cambiado. Otros aparecen vacios porque el sistema origen quiere limpiar ese dato. Si tu JSON elimina todos los campos vacios, el consumidor downstream no puede distinguir entre sin cambio y borrado explicito. Eso deja telefonos obsoletos, direcciones antiguas o ubicaciones de visita incorrectas en sistemas de destino.
La convencion mas segura es mantener la clave presente con null cuando el campo fuente esta explicitamente vacio y omitir la clave solo cuando el campo no esta representado en absoluto en la estructura parseada. Esta regla resulta especialmente util para cambios en telecom, direccion y contexto de visita dentro de mensajes A08.
Flujo de Validacion para Interfaces Reales
El flujo mas fiable es muy simple: inspeccionar el mensaje crudo, verificar la definicion del segmento, convertir a JSON y comparar los objetos derivados con el significado de negocio esperado. En la practica, eso implica abrir un ADT representativo en el Visor HL7, contrastar los campos con nuestra guia de referencia de segmentos y despues convertir ese mismo mensaje con el Convertidor HL7 a JSON para comprobar que los identificadores, nombres, clase del paciente, ubicacion, proveedores y timestamps siguen intactos.
Si tu objetivo final es FHIR, el siguiente paso es comparar ese JSON staged con las reglas de mapeo descritas en nuestra guia de pipelines de ingesta FHIR. Si tu objetivo es mejorar la lectura de mensajes, combina esta guia con nuestra introduccion para entender mensajes HL7 v2. Lo importante no es la herramienta aislada, sino que cada valor del JSON siga siendo explicable en terminos HL7.
Conclusion
Mapear PID y PV1 a JSON no es solo un ejercicio de parseo. Es una decision sobre el contrato de datos de toda la integracion. Un buen contrato preserva identidad del paciente, estado del encounter, repeticiones, contexto de proveedores, tiempos y semantica de nulos sin obligar a los equipos downstream a reconstruir lo que se perdio. Eso suele significar una capa JSON canonica inspirada en HL7 y, despues, objetos derivados mas limpios para consumo de aplicaciones.
Si quieres probar ese enfoque rapidamente, empieza con el Visor HL7 para inspeccionar un ADT real y despues convierte esa misma muestra con el Convertidor HL7 a JSON. Veras enseguida si el mapeo conserva lo que mas importa: los identificadores de PID-3, los nombres de PID-5, la clase de PV1-2, la ubicacion de PV1-3, los campos de proveedor y las fechas de visita. Cuando esos detalles sobreviven intactos, el resto del pipeline resulta mucho mas sencillo de construir y mantener.