Why PID and PV1 Matter in HL7 ADT Mapping
When teams say they are converting ADT messages to JSON, what they usually mean is that they are trying to preserve two kinds of truth at the same time: who the patient is and what encounter context surrounds that patient right now. In most HL7 v2.x admission, discharge, and transfer workflows, those truths live primarily in the PID and PV1 segments. PID carries identity and demographics. PV1 carries visit and encounter context. If either segment is flattened carelessly, the downstream JSON may still look valid while quietly losing meaning that registration systems, EMPI platforms, analytics pipelines, and FHIR mappers depend on.
This article explains how to map PID and PV1 to JSON in a way that stays operationally useful. It complements our broader guides on converting HL7 v2 to JSON, HL7 segment field references, and using HL7 JSON in FHIR ingestion pipelines. For hands-on inspection, use the HL7 Viewer to inspect raw ADT messages and the HL7 to JSON Converter to test mapping behavior in the browser.
What PID Represents in Practice
The PID segment is the demographic spine of an ADT message. It often contains the enterprise identifiers that patient matching depends on, the patient name as registration entered it, date of birth, sex, address, telecom values, and sometimes administrative details like death indicators or ethnic group codes. In real interfaces, PID is rarely a neat single-record object. Fields repeat. Components are structured. Different sending facilities populate different subsets of the segment. A JSON mapping that assumes only one identifier, one name, and one phone number will break as soon as it meets production traffic.
The safest approach is to preserve the field structure before you derive convenience properties. PID-3, PID-5, PID-11, and PID-13 are the most obvious examples. PID-3 is repeating and often contains the MRN, local facility identifier, and payer-facing identifiers in one field. PID-5 may repeat when legal and alias names are both present. PID-11 can contain multiple addresses, and PID-13 can contain more than one telecom value. If your JSON model collapses these to singular strings too early, you force every downstream consumer to guess which source repetition was retained and which were discarded.
What PV1 Represents in Practice
If PID tells you who the patient is, PV1 tells you what operational context currently applies to them. Patient class, assigned location, admission type, attending physician, hospital service, visit number, admit timestamp, and discharge timestamp all live here. For encounter-driven workflows, PV1 is the segment that decides whether downstream systems treat the message as a new inpatient stay, an ED visit, an outpatient registration, or a transfer within the same facility.
This makes PV1 especially important for analytics and FHIR transformation. A patient record without PV1 can still be useful for demographic reconciliation. A visit record without trustworthy PV1 is much harder to use. Encounter creation, census reporting, bed management, referral routing, and downstream alerting rules often depend on fields like PV1-2, PV1-3, PV1-7, PV1-19, PV1-44, and PV1-45. A JSON mapping that turns these into unlabeled strings loses the semantics needed to build reliable Encounter resources or operational dashboards.
Start with a Canonical, Lossless JSON Shape
A practical mapping strategy is to create a canonical JSON record that remains close to HL7 semantics, then derive consumer-friendly projections from it. In the canonical layer, each segment keeps its occurrence index and each field keeps its HL7 position. That means your JSON may include keys like PID.3, PID.5, PV1.3, and PV1.44 rather than immediately renaming everything to business labels. This is not because numeric field names are elegant. It is because they are unambiguous, stable, and easy to trace back to the original message during troubleshooting.
A minimal example might look like this:
{
"PID": {
"PID.3": [
["884422", "", "", ["CITY_GENERAL"], "MR"],
["99887766", "", "", ["STATE_MPI"], "PI"]
],
"PID.5": [["Lopez", "Ana", "Maria"]],
"PID.7": "19841012",
"PID.11": [["12 Harbor Ave", "", "Boston", "MA", "02110", "USA"]]
},
"PV1": {
"PV1.2": "I",
"PV1.3": ["ICU", "12", "B", "MAIN"],
"PV1.7": [["12345", "Nguyen", "Linh"]],
"PV1.19": ["VIS-20260428-17"],
"PV1.44": "20260428103000"
}
}
Once that representation exists, you can safely derive helper properties such as patient.primaryMrn, patient.legalName, encounter.class, or encounter.location.room. The key rule is that convenience fields should never be the only copy of the data.
How to Map PID-3 Without Dropping Identifiers
PID-3 is the field that exposes weak JSON mappings fastest. In many hospitals it carries multiple identifiers, each with different assigning authorities and identifier type codes. The right JSON representation is therefore an array of identifier repetitions, not a single scalar. Each repetition should preserve its internal components so that downstream logic can determine which identifier is the MRN, which is the enterprise ID, and which belongs to an external trading partner.
From that canonical array, you can derive a normalized identifier list such as:
"patientIdentifiers": [
{
"id": "884422",
"assigningAuthority": "CITY_GENERAL",
"type": "MR",
"isPrimary": true
},
{
"id": "99887766",
"assigningAuthority": "STATE_MPI",
"type": "PI",
"isPrimary": false
}
]
This derived form is easier for application code to consume, but it only works correctly if the original repetition structure was preserved first. Teams that flatten PID-3 to the first value usually discover the mistake later during patient merges, duplicate detection, or payer-facing workflows.
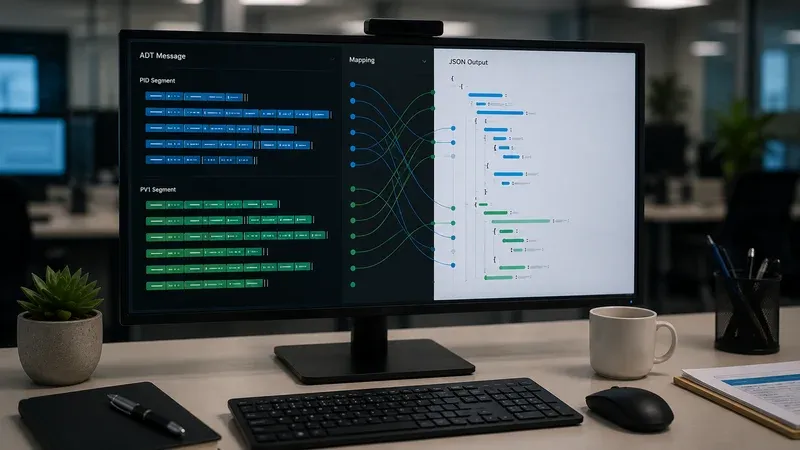
How to Map PID-5, PID-11, and PID-13
Patient names, addresses, and telecom values are composite data types with real operational nuance. PID-5 should usually be preserved as one or more XPN repetitions, even if you later publish a friendly full-name string. That lets you distinguish legal name from alias or maiden name when present. PID-11 should preserve street, city, state, postal code, country, and address type components. PID-13 should preserve the telecom structure rather than only the digits, because use codes and equipment types sometimes matter in downstream routing.
A good derived representation separates display concerns from canonical truth. For example, your application may expose patient.displayName for UI use and patient.addresses for normalized access, but still retain the source arrays keyed by HL7 field position. That approach also makes it easier to debug discrepancies with the HL7 Viewer, because analysts can compare the raw field breakdown directly with what the JSON layer preserved.
How to Map PV1-2 and PV1-3 Into Encounter Context
PV1-2 and PV1-3 are the core of visit-state mapping. PV1-2 gives the patient class. PV1-3 gives the assigned patient location. Together, they answer the most common operational question downstream systems ask: where is this patient, and in what kind of encounter? The temptation is to collapse PV1-3 into a single location string such as ICU-12-B. That is fine for display, but not enough for workflow logic. The point of care, room, bed, and facility components should remain individually accessible.
A robust derived JSON object might look like:
"encounter": {
"class": "I",
"location": {
"pointOfCare": "ICU",
"room": "12",
"bed": "B",
"facility": "MAIN"
}
}
This is the representation application teams want, but it should remain traceable to the canonical PV1.2 and PV1.3 values. When a location-routing issue appears in production, the difference between a transparent mapping and an opaque one is hours of debugging.
Provider Fields and Visit Numbers Need Structure Too
PV1-7, PV1-8, PV1-9, and PV1-17 often hold provider identities that downstream systems map into clinician directories or FHIR references. These are repeating composite fields, not just names. Preserve the identifier and human-readable components separately. The same rule applies to PV1-19, the visit number. Do not assume it is interchangeable with account number or patient identifier. In many ADT interfaces, visit number is the single best key for tying multiple movement messages to the same encounter lifecycle.
Visit timestamps matter just as much. PV1-44 and PV1-45 should retain their raw HL7 date-time forms or parsed ISO equivalents, preferably both. Analytics teams may want normalized timestamps. Interface analysts often want the original HL7 literal for audit comparison. Keeping both avoids needless arguments about which layer owns date parsing.
Null Semantics, Partial Updates, and A08 Messages
ADT updates are where lossy mapping becomes dangerous. In A08 messages, some fields are omitted because nothing changed. Other fields are present but empty because the source intends to clear them. If your JSON mapping removes every empty field, downstream consumers cannot distinguish no-change from explicit-clear behavior. That can leave stale phone numbers, outdated visit locations, or incorrect provider assignments in target systems.
The safer convention is to keep keys present with null when the source field is explicitly empty, and omit keys only when the field is not represented at all in the parsed structure. This rule is especially valuable for PID telecom and address updates and for PV1 visit-level changes where operational status matters.
Validation Workflow for Real Interfaces
The most reliable mapping workflow is simple: inspect the raw message, verify the segment definitions, convert to JSON, and compare the derived objects against expected business meaning. In practice, that means using the HL7 Viewer to inspect a representative ADT sample, cross-checking field definitions against our segment reference guide, then converting the same message with the HL7 to JSON Converter to confirm that identifiers, names, patient class, location, providers, and timestamps survived intact.
If your downstream goal is FHIR, the next step is to compare the staged JSON against the mapping rules described in our FHIR ingestion pipeline guide. If the goal is faster message literacy for analysts, pair this article with our introduction to understanding HL7 v2 messages. The important part is not the exact tool chain. It is keeping the mapping transparent enough that each field in the JSON can still be explained in HL7 terms.
Conclusion
Mapping PID and PV1 to JSON is not just a parsing exercise. It is a data-contract decision. A good contract preserves patient identity, encounter state, repetitions, provider context, timestamps, and null semantics without forcing downstream teams to reverse-engineer what was thrown away. That usually means a canonical HL7-shaped JSON layer first, followed by cleaner derived objects for application use.
If you want to test that approach quickly, start with the HL7 Viewer to inspect a real ADT message, then run the same sample through the HL7 to JSON Converter. You will see very quickly whether your mapping preserves the details that matter most: PID-3 identifiers, PID-5 names, PV1-2 class, PV1-3 location, provider fields, and visit timestamps. When those survive the trip intact, the rest of the integration gets much easier.